Qu’est-ce que le MTTR ?
Qu’est ce que le MTTR ? Pour commencer le MTTR, « Mean Time To Repair », ou « temps moyen de réparation », est l’indicateur essentiel de la compréhension qu’a un fabricant d’un outil de production. Il représente le temps moyen pour réparer et rétablir la fonctionnalité d’un système.
Ainsi, le MTTR indique notamment la simplicité de maintenance des équipements de production d’une entreprise, mais peut également s’appliquer aux applications et infrastructures, ainsi que l’efficacité de la correction en cas d’incident informatique.
Cet indicateur commence dès l’instant où une défaillance est constatée et intègre le temps de diagnostic, de réparation, de test. Aussi, toutes les autres activités permettant de remettre le service à disposition des utilisateurs finaux doivent être pris en compte.
Selon ZK Research, 90% du MTTR est consacré à simplement déterminer s’il y a réellement un problème. Une erreur de diagnostic ou des réparations inadaptées peuvent également prolonger le MTTR.
La plupart des accords de niveau de service incluent une forme de MTTR.
Il est essentiel de comprendre que le MTTR est un temps de réparation « type » et non une garantie. Les fabricants qui affichent un MTTR indiquent le temps qu’il lui faut généralement pour effectuer une réparation, mais précisent systématiquement ne pas le garantir.
Selon le contexte dans lequel il est utilisé, l’indicateur MTTR peut également désigner le temps moyen de remise en service. Dans tous les cas, le terme représente le temps requis en moyenne pour dépanner et corriger un problème.
Comment mesurer le MTTR ?
Les indicateurs de mesure du MTTR
- Les défaillances : indicateur de performance permettant à une structure de production de suivre la fiabilité de ses machines et systèmes.
- Les demandes d’assistance courantes : telles que le dépannage d’une tablette industrielle pouvant avoir un impact grave. La « défaillance » ne désigne pas seulement les dispositifs ou systèmes non fonctionnels, il s’applique également aux systèmes qui fonctionnent en mode dégradé.
- Tout système qui n’atteint pas ses objectifs peut être considéré comme défaillant.
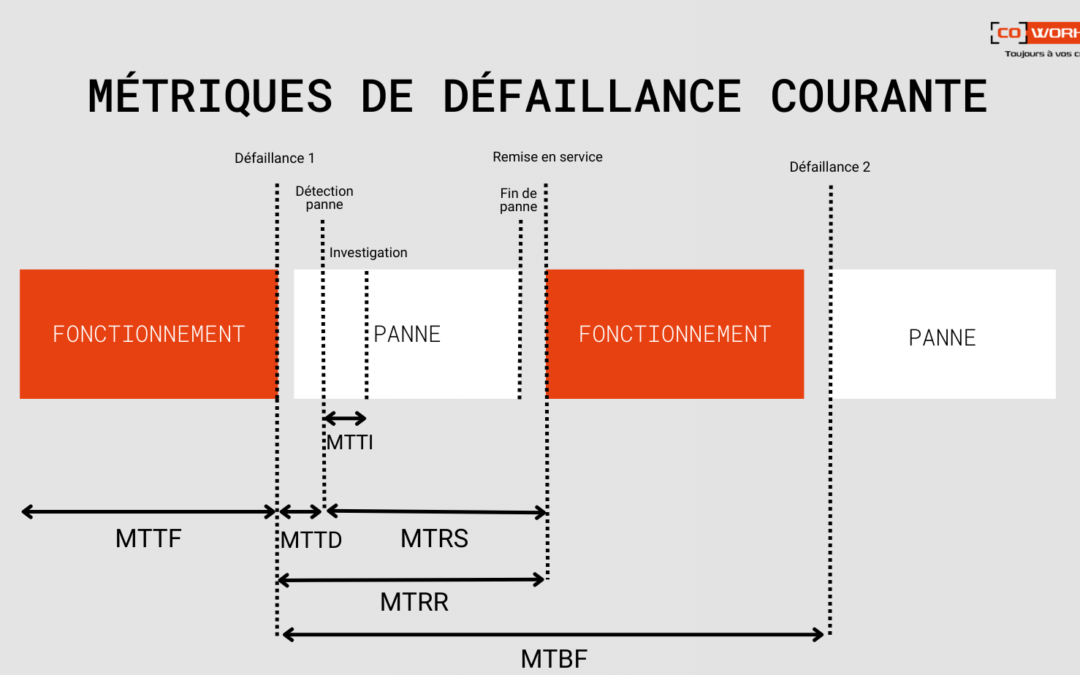
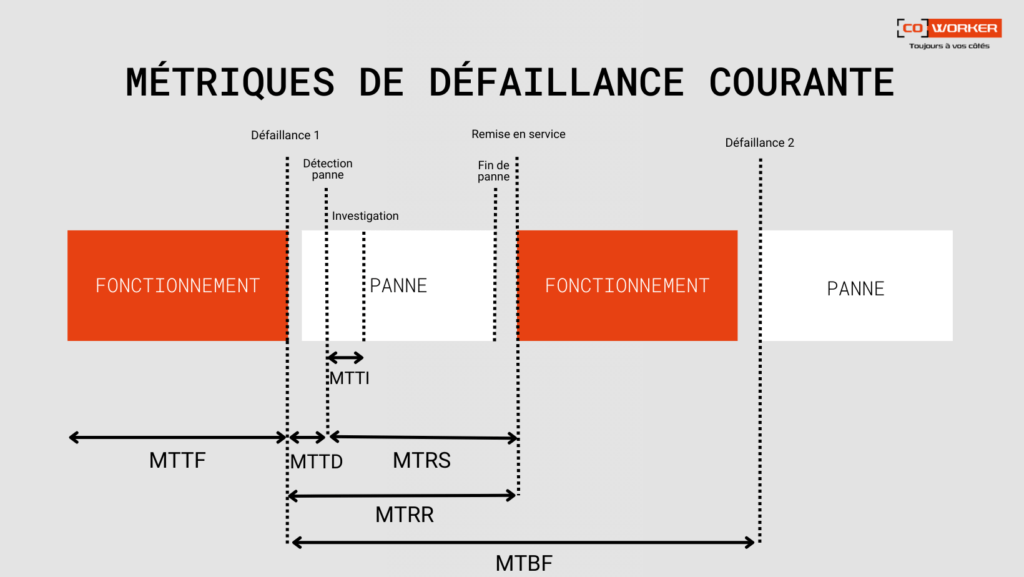
On recense plusieurs métriques de défaillance courantes :
- Temps moyen de réparation : il représente le temps moyen nécessaire pour réparer et restaurer un système défaillant.
L’indicateur de maintenance du MTTR peut se mesurer en minutes, en heures ou en jours. (Il peut également désigner le temps moyen de restauration ou le temps moyen de résolution.)
- Temps moyen entre deux défaillances (MTBF) : souvent associé au MTTR, c’est le temps opérationnel moyen entre une défaillance d’un équipement.
Les entreprises utilisent souvent MTBF comme indicateur prédictif de maintenance d’un équipement. Il est calculé en suivant le temps écoulé entre deux défaillances de système ou de composant au cours des opérations normales.
- Temps moyen avant défaillance (MTTF) : c’est la durée moyenne pendant laquelle un dispositif ou un système est censé fonctionner avant de subir une interruption de service. Souvent, les spécialistes IT recueillent ces données par observation du système pendant plusieurs jours ou semaines. S’il est similaire au MTBF, le MTTF est normalement employé pour prévoir les éléments de rechange à posséder ou à redonder à des fins d’anticipation.
- Temps moyen de détection (MTTD) : clé de voute du MTTR, il s’agit du temps moyen qui s’écoule entre le déclenchement d’un problème et le moment où l’entreprise le détecte. Il décrit la durée qui sépare le moment où l’IT reçoit un ticket et où elle démarre le compteur du MTTR.
- Temps moyen d’investigation (MTTI) : durée moyenne qui sépare la détection d’un incident IT du moment où l’organisation commence à investiguer ses causes et sa résolution. Il décrit le temps qui s’écoule entre le MTTD et le début du MTTR.
- Temps moyen de rétablissement du service (MTRS) : temps moyen qui s’écoule entre la détection d’un incident et le moment où le système ou le composant affecté est remis à la disposition des utilisateurs.
- Temps moyen entre incidents système (MTBSI) : temps moyen qui s’écoule entre la détection de deux incidents consécutifs. Il se calculer en additionnant le MTBF et le MTRS (MTBSI = MTBF + MTRS).
- Taux de défaillance : autre indicateur de fiabilité, qui mesure la fréquence à laquelle un dispositif. Il est exprimé sous la forme d’un nombre de défaillances sur une unité de temps.
Pour être efficaces, les métriques de défaillance, nécessitent la collecte d’une grande quantité de données. Il faut dire que cette tâche peut être fastidieuse si elle est réalisée manuellement, heureusement le recourt à des solutions de type MDM facilitent la collecte les données nécessaires aux calculs des métriques.
Le MTTR pour la maintenance
Le calcul du MTTR permettant de mesurer clairement la durée pendant laquelle des systèmes stratégiques de production sont hors service, il s’agit d’un indicateur de maintenance important de l’impact qu’un incident IT aura sur la production, donc sur les résultats de l’entreprise. En définitive, plus le MTTR d’une équipe IT est élevé, et plus l’entreprise court le risque de subir une coupure importante en cas d’incident avec toutes les conséquences qui en découlent.
Différence entre le MTBF et le MTTR :
Le premier indique à quelle fréquence un équipement tombe en panne, tandis que le second lui montre à quelle vitesse elle peut le remettre en service. Toutefois, ces indicateurs de maintenance peuvent être utilisés ensemble pour calculer la disponibilité d’un système. Stratégiquement, il faut à la fois réduire le MTTR et augmenter le MTBF pour minimiser ou éviter les interruptions non prévues.
Méthode de calcul du MTTR :
Il s’effectue en divisant la durée totale d’interruption par le nombre total d’interruptions. Par exemple, quand un système subit une interruption de service 4 fois dans un même mois et que ces défaillances ont entraîné 8h heures d’interruption, le résultat du calcul du MTTR est donc de deux heures
Formule du MTTR = 8 heures / 4 interruptions = 2 heures
Méthode de calcul du MTBF :
Le MTBF (Mean Time Between Failures en anglais), permet d’obtenir un indicateur de prédiction de la fiabilité et la disponibilité d’un équipement et de ses composants, la formule est la suivante :
Somme du temps de fonctionnement divisé par le nombre de pannes.
Formule du MTBF = 8 heures / 2 interruptions = 4 heures

Interprétation et application du MTTR
Lorsqu’il est faible, le MTTR indique qu’un produit ou un service peut être réparé rapidement, et donc que tous les problèmes informatiques associés n’auront probablement qu’un faible impact sur l’entreprise.
Lorsqu’il est élevé, il doit inciter les administrateurs IT et directeurs de production à réévaluer leur approche du dépannage en tenant compte du cycle de vie, de la méthode de surveillance et de diagnostic, dans le but de réduire les interruptions potentielles.
Comment réduire le MTTR ?
Si la plupart des problèmes qui le font augmenter sont propres à chaque entreprise, on peut recommander quelques étapes qui permettront à tous les types d’organisation ou presque d’améliorer leur MTTR.
- La compréhension des incidents :pour le réduire, il faut comprendre les incidents et les défaillances. Les rapports d’audit peuvent vous aider à unifier automatiquement vos données en silos pour obtenir un indicateur de maintenance fiable et des informations précieuses sur les causes et les facteurs de cette métrique stratégique.
- La supervision : pour améliorer les métriques et corriger un problème, il faut les identifier. Le plus tôt sera le mieux. Une bonne solution UDM (Unified Device Management) vous fournira le flux continu de données sur les performances de votre système, généralement au sein d’un même tableau de bord facile à lire, et vous avertira de l’apparition des problèmes.
- Le process d’actions : utiliser des outils de collaboration inter-fonctionnels pour apporter une réponse spécifique à chaque incident. Dans tous les cas, il doit indiquer clairement les personnes à informer en cas d’incident, comment le documenter et la marche à suivre par votre équipe pour le résoudre.
- La gestion des incidents :répondre rapidement nécessite, les bonnes personnes, des informations précises sur le problème. Un système automatisé de gestion des incidents peut envoyer simultanément des alertes sur plusieurs canaux de communication aux interlocuteurs clairement identifiés. Cette automatisation permet d’améliorer le facteur de communication faisant partie intégrante des métriques de mesure du MTTR.
- Equipe, compétences et rôles : Les rôles, les compétences et les responsabilités bien établis permettent de gérer efficacement la réponse aux incidents et de réduire le MTTR. La structure de l’organisation dépend bien entendu de la taille de l’entreprise et de ses compétences intrinsèques. Dans le cas d’une sous-traitance, le choix du prestataire nécessite d’en vérifier la compétence particulièrement dans la connaissance de l’ ITIL (maîtrise du modèle de la structure informatique). Interne ou externalisée elle doit intégrer :
- Un gestionnaire d’incidents : ce rôle dirige le processus de gestion des incidents, l’adapte et l’améliore au besoin. Ce rôle est généralement confié au responsable du service d’assistance dans les petites et moyennes entreprises. Il dirige également l’équipe d’intervention. Il présente le MTTR, à la direction et gère l’assistance de Niveau 1 et 2.
-
-
- Niveau 1 : ce rôle est le point de contact unique pour les utilisateurs finaux qui signalent les incidents. Il classifie les incidents et doit s’efforcer de restaurer le service défaillant au plus vite.
- Niveau 2 : les techniciens de second niveau sont plus pointus. Ils sont mobilisés pour les incidents qui ne sont pas à la portée technique du niveau 1. Ils sont également chargés d’interagir avec les fournisseurs tiers pour accélérer le rétablissement des services. Plus l’infrastructure est complexe et plus le nombre de niveaux est grand.
-
- La formation :Les connaissances très ciblées sont la clé du bon fonctionnement des équipes, l’IT évoluant en permanence les plans de formation ont un rôle stratégique
L’impact du MTTR, une priorité chez COWORKER®
Pour conclure, les entreprises utilisant les équipement COWORKER comme outils de production, ont des niveaux de service exigeants car l’impact sur cette production sont élevés. Tout en réduisant les coûts de possession, les délais de réponse et traitement des incidents acquièrent une importance cruciale. Si MTTR ne fournit qu’une indication du temps de remise en service, il s’agit cependant d’un indicateur de maintenance fiable de la capacité des équipes de YATOO à répondre rapidement et à réparer des problèmes potentiellement coûteux.
YATOO propose une gamme d’offre de services destinés aux professionnels : conseil, configuration, maintenance jusqu’à la gestion de fin de vie des équipements, YATOO vous accompagne ses clients dans leur projet de mobilité. Découvrez les offres de services destinées aux professionnels.
Ainsi, dans des usages où l’impact direct des interruptions de production, la rentabilité et la confiance des clients, une solide compréhension du MTTR, ou Mean Time To Repair, et de ses composantes est un impératif de transparence dans le choix de nos produits.
Découvrez l’ensemble de la gamme de tablettes Coworker.